Computationally-driven text analysis is utilized in a variety of disciplines and connects humanist scholars to linguists, social scientists, computer scientists, and statisticians. Text analysis looks at elements such as word frequencies, co-occurrence, and statistically generated ‘topics’ to perform ‘distant reading’ of large collections (such as a corpus of 2,958 19th century British novels or 70+ years of Houston newspapers). Digital humanists usually perform this analysis with the help of algorithms developed by computer scientists, statisticians, and linguists. Depending on the individual researcher’s level of programming skill, they can make use of specialized text analysis libraries in the Python or R programming languages, or use out-of-the-box tools like MALLET and Paper Machines.
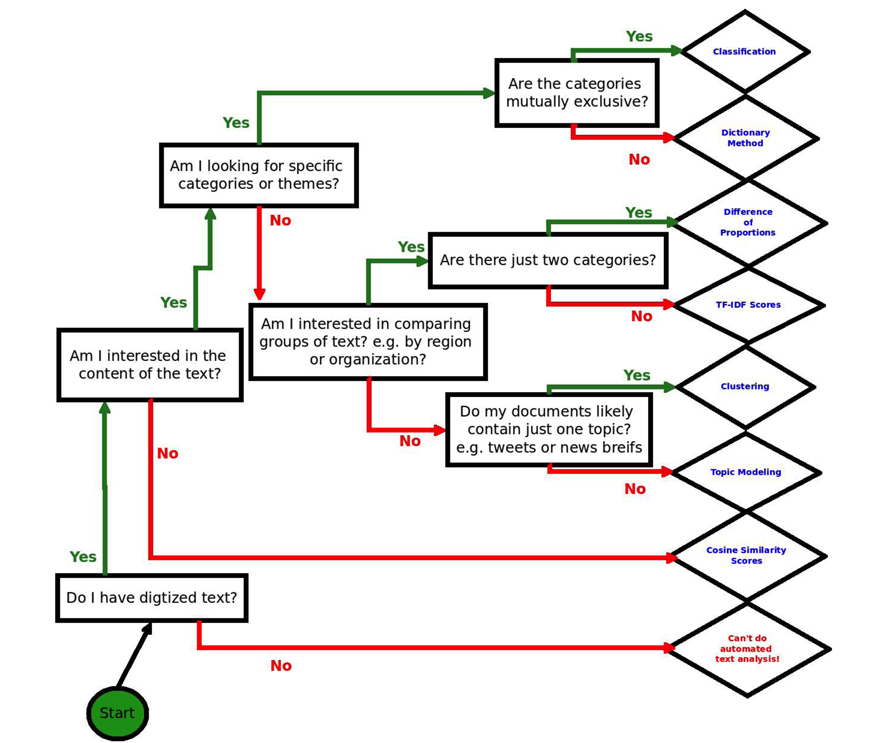
“Text analysis” usually describes an umbrella of techniques, such as topic modeling and clustering. The flowchart below, created by Laura K. Nelson for a workshop at the D-Lab titled “Intro to Text Analysis – When and How to Use It”, provides a rough taxonomy of techniques (see image).
For an introduction and some examples of text analysis applications in DH, see the Journal of Digital Humanities’ issue on topic modeling. Pamphlets published by Stanford Literary Lab also offer accessible but thorough discussions of text analysis methods, research design, and comparisons with traditional, ‘close reading’ scholarship.
Training
D-Lab
The D-Lab offers is always expanding its workshop offerings. The D-Lab offers many workshops that on skills that complement text analysis projects, such as web scraping and introductions to the Python and R programming languages. D-Lab consultants are currently working on expanding offerings in text analysis workflows, such as pre-processing corpora and R packages specific to text analysis work.
Computational Text Analysis Working Group (CTAWG)
The Computational Text Analysis Working Group is an interdisciplinary community interested in exploring text analysis methods. Currently, TAWG focuses on using text analysis packages in the R programming language and stores tutorials on a public Github repository.
Information 256: Applied Natural Language Processing
This graduate division course at the School of Information is a good option for those who are interested in pursuing an in-depth project in text analysis. The course requires decent proficiency in the Python programming language. Students are advised to take Information 153: Introduction to High-Level Programming (offered during the summer) or equivalent training.
Summer Training
Digital Humanities Summer Institute at the Univeristy of Victoria
Researchers looking for DH-specific training and applications of these tools are also invited to explore course offerings at the Digital Humanities Summer Institute at the University of Victoria. One of the largest gatherings of digital humanists in North America, DHSI week-long intensives in a variety of topics and digital methods, such as “Stylometry with R: Computer-Assisted Analysis of Literary Texts” and “Understanding Topic Modeling”. Learn more about scholarship applications and discounted tuition available to all UC Berkeley affiliates.
Digital Humanities at Berkeley Summer Institute
A week-long intensive on computational text analysis is also taught at the DH at Berkeley Summer Institute.
Consulting & Services
Data
For help with web scraping (downloading material from the internet in a controlled, semi-automated manner), designing databases for storing text, and cleaning data for processing, an appointment at the Doe Library Data Lab or a D-Lab consultant may be useful.
Guide to Library Sources for Text Analysis
Most library-licensed online resources, unfortunately, do not yet support text analysis applications or permit web-scraping. This guide, however, tracks the academic sources that do provide access to text in formats to support various text analysis methods. The guide also includes an introduction to using HathiTrust Research Center (HTRC) tools for computational research access to the HathiTrust Digital Library.
Software
For a discussion about R packages and Python libraries useful for text analysis, researchers may want to contact consultants at the Social Sciences D-Lab or bring their questions to the the Text Analysis Working Group.
Hardware
Depending on the size of the corpus or the nature of analysis, text analysis jobs can sometimes require several hours or even several days of computing time on a standard laptop. If this becomes an issue, please consult with D-Lab staff about gaining access to more powerful hardware or cloud computing services.
Resources
Other Resources
- MALLET is a package for statistical natural language processing, document classification, clustering, topic modeling, information extraction, and other machine learning applications to text.
- Paper Machines is a tool that allows researchers to create visualizations of their Zotero libraries and, with collections of more than 1000 documents, perform topic modeling.
- The Programming Historian offers an introduction to topic modeling with MALLET, as well as other tutorials on web scraping and data manipulation.
- The Natural Language Tool Kit (NLTK) is a Python library used for text analysis. The Creative Commons-licensed book, Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit offers users an accessible introduction to text analysis without assuming programming experience.
- Researchers who are looking for more text analysis tools should consult DiRT Directory (a tool registry for the digital humanities community), as well as tools and recipes listed at the Text Analysis Portal for Research (TAPoR).